
좋은 책은 독자에게 많은 통찰을 준다. 박태웅 의장이 하는 강의나 그의 책은 늘 새로운 뭔가를 깨닫는 시간을 제공한다. 이 책 『박태웅의 AI 강의 2025』은 인공지능을 분해해서 독자들이 잘 이해할 수 있는 수준으로 설명한다. 그럼에도 일부는 어렵다.
개인적으로 회사에서 업무를 위해 챗GPT를 사용하고 있다. 그래서 챗GPT의 능력을 매일 접한다. 이전에는 구글에서 검색하는 시간이 많이 걸렸다. 하지만 지금은 모르는 공학용어나 약자가 나오면 바로 챗GPT에 묻는다. 그러면 바로바로 대답해 준다. 다만, 가끔은 직접 내용을 검증해 봐야 할 경우가 있다.
마지막 부분에 한국정부가 하지 말아야 할 일 부분은 다시 한번 안타까운 마음이 들었다. 2023년 7월, 정부는 33년 만에 처음으로 R&D 예산을 대폭 삭감했다. '이권 카르텔'이라는 실체도 공감하기 힘든 부분을 강조하며 일방적으로 선언했다. 이로 인한 후폭풍은 컸다. 미국과 캐나다 등에서는 인공지능과 관련 산업이 함께 급속히 성장하는 시대다. 우수한 연구인력이 중요한 시대다. 하지만 예산삭감으로 인해 우수 연구인력의 유출이 심화되었다. 안타까운 우리의 현실이다.
박태웅 의장이 전하는 메시지는 늘 명확하다. 그의 진심이 담긴 책이다. 대한민국의 위정자들은 이 책을 통해 정책의 방향을 세울 수 있다. 대한민국의 청년들은 이 책을 통해 기본의 중요성을 깨닫고 자신의 삶의 방향을 찾아볼 수 있다. 대한민국의 기업에서는 인공지능의 현주소를 냉철하게 바라보며 기업에서 활용할 방향을 찾을 수 있겠고 우수 인력 육성 및 채용 방안에 대해서도 참고할 수 있다.
아래는 책에서 남기고 싶은 문장을 인용했다.
토큰은 단어를 컴퓨터가 처리할 수 있게 숫자로 표시한 것입니다. 컴퓨터는 이진법을 쓰므로 모든 입력은 숫자로만 가능합니다. 그래서 단어들에 숫자를 매겨, 이를테면 강아지는 12, 고양이는 5, 이런 식으로 표시하는 것입니다. 이렇게 하면 이진법으로 입력할 수 있겠지요. 많이 쓰이는 접두사, 접미사와 같은 경우에도 따로 숫자로 표기합니다. 가령 늦가을, 맏형과 같은 경우는 '늦', '맏'을 다로 떼내서 숫자로 표기하는 것이지요. 자주 쓰이는 접두사, 접미사들을 이렇게 별도로 표기하면 나중에 처리하기가 더 수월해집니다. 이런 이유로 단어 숫자보다 토큰 숫자가 더 많습니다. (42)
인공지능에는 규모의 법칙이란 게 있습니다. 컴퓨팅 파워를 더 많이 넣을수록, 학습 데이터를 더 많이 넣을수록, 매개변수를 크게 잡을수록 인공지능의 성능이 더 좋아지더라는 것인데요, 지금까지는 최적의 비례라는 게 있어서 셋이 함께 커질 때 효율이 높다고 돼 있었습니다. 실제로도 그렇고요. 그런데 메타는 매개변수는 작게 둔 채로 학습 데이터를 무려 50배나 더 많이 넣어버린 것입니다. 그러니까 최적의 비례가 아닌 것이지요. 더 놀라운 것은 메타가 아직 규모의 법칙의 끝을 보지 못했다고 밝혔다는 것입니다. 그러니까 그만큼 집어넣었는데도, 여전히 더 많은 학습 데이터를 넣으면 품질이 더 좋아질 여지가 있더라는 것입니다. (48)
휴머노이드를 만드는 또 하나의 특별한 이유가 있습니다. 이런 종류의 휴머노이드 로봇을 '몸을 지닌 AI Embodied AI'라고 부릅니다. '몸을 가진'이 무슨 뜻일까요? 인공지능이 제대로 '지능'이 되기 위해서는 '몸'을 가지고 있어야 한다고 주장하는 AI 과학자들이 있습니다. 그래야 세계에 관환 모델World Model을 가질 수 있다는 것입니다. 세계에 관한 모델은, '외부 세계가 실제로 어떻게 생겼다'는 것에 관한 지각을 말합니다. (...) 그러자면 환경과 실제로 상호작용을 하며 세계를 인지할 '몸'을 갖고 있어야 한다는 것입니다. (64)

인공지능 알고리듬 중에 몬테카를로 알고리듬 Monte Carlo algorithm이란 게 있습니다. 가령 다음과 같은 문제가 있다고 해보지요.
한 변의 길이가 2미터인 정사각형에 내접한 원의 넓이를 구하시오.
우리는 이 원의 넓이를 쉽게 계산할 수 있습니다. (...)
그런데 인공지능은 이렇게 구하지 않습니다. 몬테카를로 알고리듬은 정사각형 속에 무작위로 발생시킨 점을 쏩니다. 수십만 개, 수백만 개를 쏜 다음, 전체 점의 숫자에서 원에 들어간 숫자의 비율을 구합니다. (...) 그런데 이렇게 구하는 게 반지름의 제곱 × 원주율(π)로 구한 것보다 빠릅니다. 이 녀석은 1초에 312조 번 실수 계산을 할 수 있기 때문입니다. (76)
그러나 이 방식도 쉽지는 않습니다. 우선, 편향되지 않은 질문과 대화를 할 수 있는 고급 평가자들을 고용하기가 어렵습니다. 이들을 고용하는 데 돈도 많이 듭니다. 평가자들 간에 편향도 없어야 합니다. 평가자들 간에 점수를 매기는 기준이 들쭉날쭉해버리면 챗GPT가 제대로 배울 수 없기 때문입니다. 개발자와 평가자 간에도 기준이 같아야 합니다. 5만 개의 높은 품질의 질문과 답변을 만드는 데도 시간과 돈이 아주 많이 들어갑니다. <뉴욕타임스> 보도에 따르면 챗GPT를 학습시키는 데 거의 3.7조 원 정도가 들었다고 합니다. (93)

아무런 예제 없이 묻는 질문에 답하는 것을 제로 샷 러닝 Zero shot Learning, 몇 가지 예제와 함께 질문할 때 답하는 것을 퓨 샷 러닝 Few shot Learning이라고 한다. 이 둘을 합해 질문 속에서 배운다는 뜻으로 인 콘텍스트 러닝 Context Learning ICL이라고 부릅니다. (144~145)

다음 그림은 셰인 포자드라는 개발자가 정리해서 올린 '초보자를 위한 프롬프트 잘 쓰는 법'입니다. 늘 작 먹히는 대표적인 프롬프트들은 다음과 같습니다.
"차근차근 생각해보자"처럼 단계적 추론을 유도하는 말을 덧붙이거나,
"네가 OOO (예: 생물학자, 변호사, 마케터...)라고 가정하자"처럼 역할을 부여하거나,
"ㅁㅁㅁ를 표로 만들어줘"처럼 포맷을 지정하거나,
"△△△를 요약하고 가장 중요한 것 여섯 가지를 나열해줘"처럼 구체적으로 일을 지정할 때 좋은 결과가 나옵니다. (158~159)
워싱턴대학교의 최예진 Yejin Choi 교수가 TED 강연에서 공개한 에피소드도 흥미롭습니다. 그의 강연 제목은 <왜 인공지능은 믿을 수 없을 정도로 똑똑하면서 충격적으로 멍청한가 Why AI Is Incredibly Smart and Shockingly Stupid>입니다. 아주 흥미롭습니다. 시간도 짧으니 꼭 보기를 권합니다. 최 교수가 GPT-4에게 던진 세 가지 질문의 소개합니다. (...) 최 교수는 AI에게 상식을 가르쳐야 할 것이라고 말합니다. 그는 우주를 구성하고 있는 암흑 물질과 암흑 에너지에 빗대어 설명합니다. (...) 그는 세상이 어떻게 돌아가는지에 관한 상식적인 이해를 가르치지 않고서는 인공지능이 제대로 작동할 수 없을 것이라고 단언합니다. (165~168)
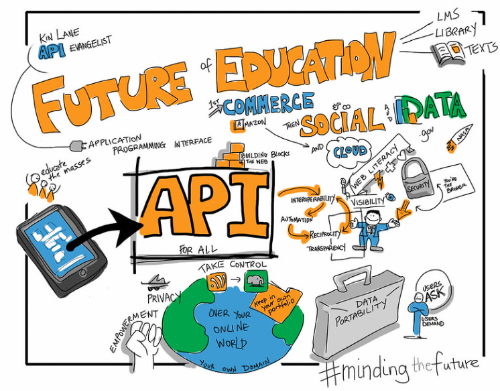
챗GPT가 이런 서비스들을 쓸 수 있게 된 것은 API Application Programming Interface 덕분입니다.(...) API는 말하자면 프로그램 간의 인터페이스입니다. 프로그램끼리 소통할 수 있도록 만든 규약이라는 뜻입니다. "내가 발급한 API를 사용하여 요청을 하면 정해진 포맷대로 데이터를 주거나, 정해진 행동을 하겠다"라는 것입니다. API를 쓰면 사람임 개입하지 않고도 컴퓨터 간에 자동으로 정해진 데이터를 받거나 정해진 결과를 얻을 수 있습니다. 자동화가 가능해지는 것이지요. (176)
공공데이터를 공개할 때 반드시 API를 함께 만들어서 공개하라고 하는 것이 바로 이 때문입니다. 효율을 비할 바 없이 높일 수 있기 때문이지요. (...) 챗GPT와 GPT-4도 물론 API를 공개했습니다. 세상의 모든 소프트웨어 회사들이 이것을 통해 챗GPT와 GPT-4를 쓸 수 있게 된 것이지요. (177)
오픈 어시스턴트Open Assistant가 RLHF(인간의 피드백을 통한 강화학습)를 통한 정렬을 위한 데이터 세트와 이를 통해 학습한 모델을 출시합니다. 이 모델은 사람 선호도 측면에서 챗GPT와 비슷합니다. (48.3퍼센트 대 51.7퍼센트). 이 데이터 세트는 라마 외에도 피티아-12B Pythia-12B(오픈소스 거대언어모델)에 적용될 수 있으며, 완전히 개방된 스택을 사용해 모델을 실행할 수 있는 옵션을 제공합니다. 또한 이 데이터 세트는 공개적으로 사용 가능하기 때문에 소규모 실험자들도 저렴하고 쉽게 RLHF를 사용할 수 있습니다. (195)
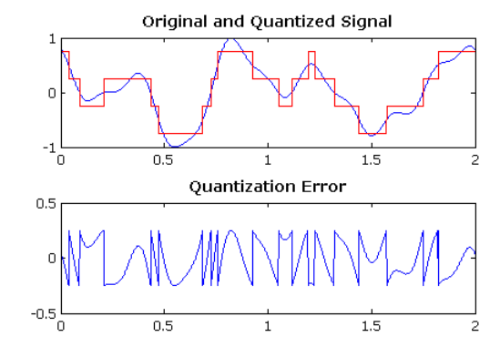
거대언어모델의 매개변수는 대개 32비트 부동소수점으로 표기합니다. 이를 16비트 부동소수점으로 변환하면 모델 크기를 절반으로 줄일 수 있습니다. 8비트 정수로 변환하면 모델 크기를 4분의 1로 줄일 수 있겠지요. 이를 '양자화 Quantization'라고 합니다. 이렇게 하면 정확도는 떨어지겠지만 처리 속도가 올라가고 에너지를 덜 쓸 수 있게 됩니다. 경우에 따라 모바일 기기에도 올릴 수 있습니다. (197)

민스키는 의식이 이러한 여러 에이전트들의 상호작용의 결과로 나타난다고 주장하며, 자아는 이러한 상호작용에서 나온 일종의 허구적인 개념이라고 봅니다. 그의 이론을 가장 잘 표현한 것은 그의 책에 나오는 다음 문장입니다.
어떤 마술 같은 비결이 인간을 지능적으로 만드는가? 그 비결은 비결이 없다는 것이다. 지능의 힘은 어떤 단 하나의 완전한 원리가 아니라 우리의 광대한 다양성을 바탕으로 한 것이다.
마음을 단일한 실체가 아닌, 다양한 에이전트들의 사회적 상호작용으로 보는 그의 관점은 인공지능 연구와 인지과학에 큰 영향을 미쳤습니다. 현대의 인공일반지능AGI에 대한 논의와 정의가 많은 경우 의식, 자의식을 아예 다루지 않는 데는 분명히 민스키의 영향이 있었을 것입니다. (211)

스택오버플로 Stack Overflow라는 사이트가 있습니다. "모든 개발자는 스택오버플로로 탭을 열어두고 있습니다"라는 캐치프레이즈를 자랑하는 곳입니다. 전 세계의 개발자들이 개발을 하다 궁금한 게 생기거나 막힌 곳이 있으면 물어보고 답하는 게시판입니다. 개발자를 위한 네이버 지식인과 같은 곳이지요. 챗GPT가 발표된 뒤 이 스택오버플로의 방문자 수가 급감하기 시작했습니다. (...) 문제는 챗GPT가 프로그래밍을 학습한 대상이 바로 이 스택오버플로였다는 겁니다. 온라인 코드 저장소인 깃허브 GitHub와 스택오버플로는 인공지능이 개발 공부를 하기 가장 좋은 두 개의 사이트였습니다. 그렇게 공부한 챗GPT가 스택오버플로의 트래픽을 빼앗가가고 있는 것입니다. (255~256)
유럽연합에는 녹서Green Paper라는 제도가 있습니다. 사회적으로 함께 답을 찾아야 할 어떤 일이 있을 때 '그 일에 제대로 대처하기 위해서 우리는 어떤 질문에 대답해야 하는가?'라는 것, 그러니까 우리가 답해야 할 질문들을 모아서 묶은 보고서입니다. 처음부터 제대로 된 질문을 찾지 못하면, 올바른 답을 할 수가 없다는 것입니다. 아주 당연하지만 그만큼 어려운 이야기입니다. 정부가 녹서를 내놓으면 전체 사회가 함께 그 질문들에 대한 답을 찾습니다. 이런 과정을 몇 년간 거치고 나서야 정부는 공론화를 통해 모인 답을 묶어 보고서를 내놓습니다. 이게 바로 백서 White Paper입니다. 그러니 몇 명의 전문가나 공무원들이 몇 달 정리해서 후다닥 내놓는 우리 백서와는 차원이 다를 수밖에 없지요. 같은 건 백서라는 제목뿐이라고 할까요. (269)

42년 전인 1975년 2월 아실로마에 폴 버그, 맥신 싱어 등 세계적인 생물학자와 변호사, 의사들이 모입니다. 이들은 당시 새롭게 떠오르던 유전자 조작(재조합 DNA Recombinant DNA) 기술의 안전을 보장하는 자발적 지침을 작성했습니다. 생명공학의 잠재적 생물학적 위험을 느끼고 그것에 대한 규제의 필요성을 논의하는 자리였습니다. (...) 인공지능 과학자들이 42년 뒤 같은 장소에 모인 것은, 인공지능이 재조합 DNA만큼이나 강력하고 위험한 신기술이며, 인류가 다시 한번 집단지성을 발휘할 수 있으리라는 기대 때문이었습니다. 아실로마는 6년 뒤 한 번 더 모임의 배경이 됩니다. 2023년 3월, 스튜어트 러셀, 일론 머스크, 스티브 워즈니악 등 일군의 AI와 IT 전문가들이 '거대한 인공지능 실험을 멈춰라'라는 성명을 발표합니다. (280~283)
'인공지능이 자동으로 편집을 하기 때문에 사람은 책임이 없다'는 설명은 애초에 틀린 말이기도 합니다. 편집 알고리듬을 만들기 위해서는 목적함수를 설정해야 합니다. 어떤 게 좋은 편집이라는 것을 알려줘야 한다는 것이지요. 그리고 그런 기준은 사람이 정할 수밖에 없습니다. 앞서 정리했던 인공지능 윤리의 여덟까지 기준 가운데 하나는 '책임성'입니다. '어떤 경우에도 인공지능에 책임을 물어서는 안 된다. 책임지는 사람이 있어야 한다'는 것이지요. (296~297)

토비 오드Toby Ord의 《사피엔스의 멸망 The Precipice》은 장기주의 철학을 대표하는 책입니다. 이 책은 인류가 직면한 실존적 위험에 초점을 맞춰, 우리의 장기적 생존과 번영을 위협하는 요소들을 분석합니다. 그는 기후 변화, 핵전쟁, 인공지능, 생물학적 위험 등 위험들의 확률을 추정하고, 이를 바탕으로 우리가 취해야 할 행동의 우선순위를 제안합니다. (352~353)
한국 정부가 해야 할 일
기초과학을 육성해야 합니다. 인공지능 알고리듬은 수학을 모르고선 도리가 없습니다. 인공지능 과학자 중에 수학과 물리학을 전공한 사람이 많은 것은 그 때문입니다. 현대의 인공지능은 인간의 뇌를 흉내 낸 것입니다. 인지심리학, 뇌과학의 배경 없이 제대로 만들기가 어렵습니다. (...)
연구개발에 대한 지원도 바뀌어야 합니다. (...) 정부의 연구개발 예산 지원은 긴 호흡으로 해야 합니다. 성공 가능성이 낮지만 꼭 해야 할 분야에 들어가야 합니다. 유행처럼 주제를 따라가지 말고, 연구자를 육성하는 게 목표가 돼야 합니다. 그래야 비록 실패하더라도 소중한 경험을 쌓은 연구자는 남기 때문입니다.
전문가들의 지식을 최대한 반영할 수 있는 통로가 마련돼야 합니다. 과학과 기술읜 발전이 가속도를 붙이면서 모든 영억이 갈수록 전문화가 되고 있습니다. (...) 일반 행정가인 공무원이 판단을 내리기가 점점 더 어려워진다는 뜻입니다. (...)
정부가 과학과 기술 정책의 호흡을 바꾸지 않고, 후발 추격국의 태도와 전략을 버리지 못한다면 우리는 머지 않아 다시 '눈 떠보니 후진국'이 되어버릴지도 모릅니다. (391~396)
독서습관 1009_박태웅의 AI 강의 2025_박태웅_2024_한빛비즈(250216)
■ 저자: 박태웅
KTH, 엠파스 등 IT 분야에서 오래 일했다. 한빛미디어 이사회 의장을 거쳐 현재 녹서포럼 의장을 맡고 있다. 녹서포럼은 당대 사회가 반드시 답해야 할 질문들, 정의 내려야 할 문제들을 드러내는 토론과 공론의 장이다.
2021년 정보통신분야 발전에 기여한 공로를 인정받아 동탑산업 훈장을 수상하였다. 저서로 《눈 떠보니 선진국》, 《박태웅의 AI 강의》 등이 있다.
'독서습관' 카테고리의 다른 글
| [1011]碑銘을 찾아서 : 京城 쇼우와 62년_이토 히로부미가 살고 일본이 한반도를 지배한다면 (0) | 2025.02.25 |
|---|---|
| [1008]설국_도쿄의 시마무라가 만난 설국의 고마코의 정열과 요코의 순정 (0) | 2025.02.15 |
| [1010]나이? 유쾌한 반란_아침마다 두근두근 설레는 노년을 위한 글 (1) | 2025.02.15 |
| [1007]종이달_물질주의 속 개인과 가족의 행복을 향한 길에 대한 질문 (1) | 2025.02.14 |
| [1005]청춘의 문장들_35세의 김연수를 만든 이전의 흔적들 (1) | 2025.02.04 |




댓글